
GPUとConfidential Computingを利用した、安全な生成AIのすすめ
公開日:2026.07.03

.png)
こんにちは。Acompany エンジニアのキタヤです。
生成AIの活用が組織の生産性に直結する今、データの安全性は避けて通れないテーマです。本記事では、生成AIを業務で安全に活用するための考え方を、Acompany が採用している技術要素も交えながら解説します。
1. なぜ今「安全な生成AI」が必要なのか
生成AIを業務活用するにあたり、代表的な選択肢には SaaS 型 LLM とローカル LLM がありますが、それぞれに課題があります。
SaaS 型 LLM(Gemini などのクラウドAPI) は導入が容易で高性能ですが、入力したプロンプトや出力はサービス提供者の管理する基盤を経由します。エンタープライズ向けサービスでは学習利用を制限できる場合もありますが、データの保存、ログ、障害対応、不正利用検知などの具体的な扱いは、契約・設定・提供者の運用に依存します。そのため、機密情報・個人情報を扱う業務では、利用者側から処理内容を実装レベルで検証しづらい点が課題になります。
なお、AI/機械学習一般では、収集データの二次利用をめぐる問題も過去に発生しています。たとえば写真保存アプリ Ever の事例では、FTC との和解により、データだけでなく、それをもとに開発された顔認識モデル・アルゴリズムの削除も求められました。
ローカル LLM(オンプレ/自社GPU) はデータを外に出さずに済むため秘匿性に優れます。一方で、ハードウェアレベルでのセットアップやモデル・実行環境の更新を自社で行う必要があり、サーバーへの侵入やサプライチェーン攻撃など想定すべき脅威も自社で対処する必要があります。高い秘匿性と引き換えに、相応の運用体制が求められる選択肢といえます。
つまり、SaaS 型は運用を軽くしやすい一方で提供者の運用を信頼する部分が残り、ローカル型は自社統制を強めやすい一方で運用負荷が増えやすい、というトレードオフがあります。この記事では、その第三の選択肢として Confidential Computing(以下、CC)を用いた GPU 上の LLM 推論 を紹介します。
2. Confidential Computing とは
Confidential Computing(CC)は、単一の製品名や特定技術の呼称ではなく、TEE と呼ばれるハードウェアベースの隔離実行環境を用いて「処理中のデータ」を保護する計算パラダイムです。従来の暗号化は「保存時(ディスク)」「通信時(ネットワーク)」を守るものでしたが、CPU/GPU が計算する瞬間はメモリ上に平文で展開されるのが普通でした。CC はこの処理中の状態を保護することを目的としたアプローチです。
- TEE(Trusted Execution Environment):CPU や GPU などのハードウェアの支援により、通常の OS・ハイパーバイザー・他プロセスから隔離される実行領域です。TEE 自体は「隔離された実行領域」を指す概念であり、すべての TEE がメモリ暗号化を伴うわけではありません。たとえば TrustZone のようにメモリ暗号化を前提としない TEE も存在します。本稿では、クラウド上で LLM 推論を行う文脈に絞り、メモリ暗号化や Remote Attestation を備えたサーバー向け TEE を主な対象とします。
- GPU での CC(CC 対応 GPU、以下 CC GPU):従来、CC は CPU ワークロードを中心に発展してきましたが、NVIDIA H100 などの CC 対応 GPU により、LLM 推論のような GPU ワークロードでも、GPU メモリや CPU-GPU 間のデータ経路を保護対象に含められるようになってきました。本稿では、こうした GPU を CC GPU と呼びます。
- Remote Attestation(リモート構成証明):接続先の実行環境が、期待した TEE / CC GPU 上で、想定したソフトウェア構成を実行しているかを外部から検証する仕組みです。ハードウェアやファームウェアに紐づく鍵を信頼の起点として、実行環境の測定値を含むレポートを署名付きで検証します。これにより、利用者は提供者の説明を信じるだけでなく、通信相手の実行環境を技術的に確認できます。
3. CC 上で LLM を動かす利点
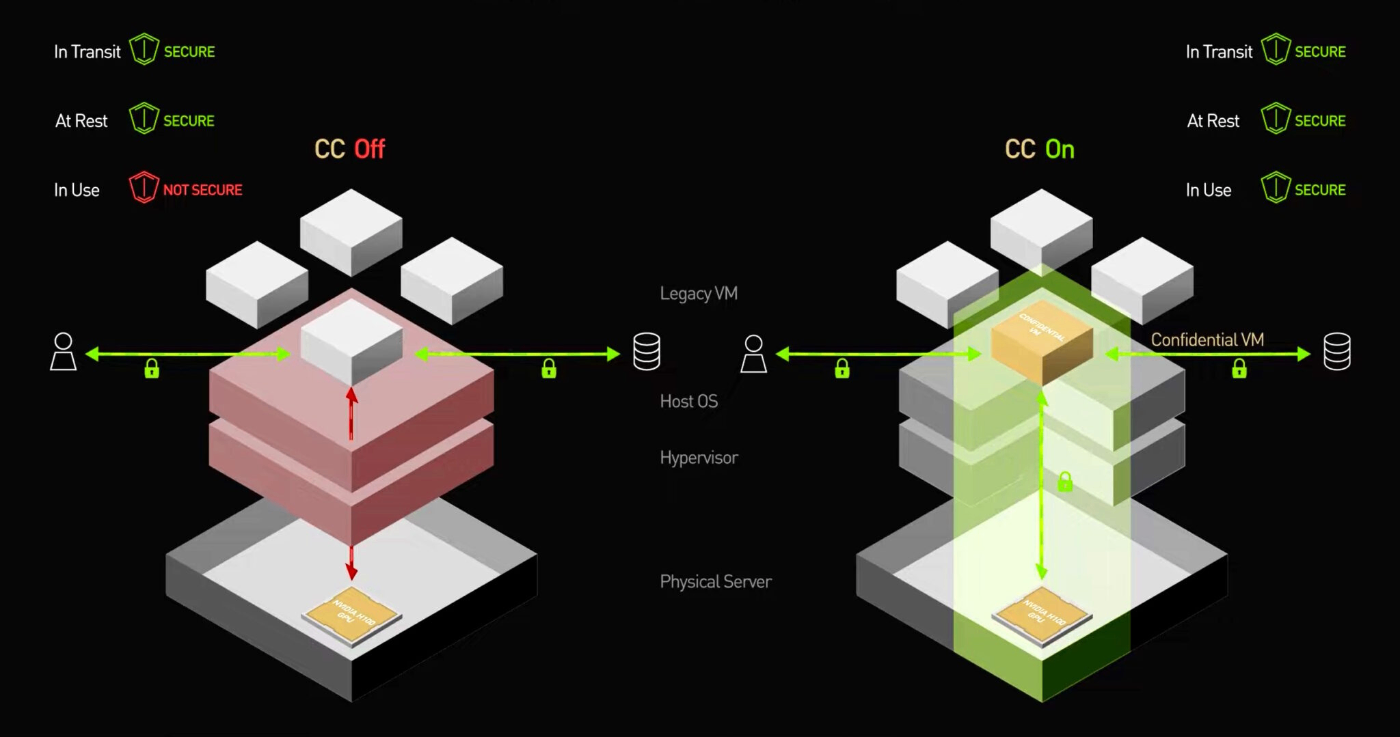
特権管理者・侵害されたホストからのメモリ読み取りに強い
本記事で想定するような、メモリ暗号化を備えた TEE / CC GPU では、処理中のデータが TEE の外側から直接読み取られにくいように設計されています。そのため、クラウド事業者の特権管理者や、ホスト OS・ハイパーバイザー側の権限を得た攻撃者であっても、メモリダンプなどを通じて入力プロンプト・推論結果・モデルパラメータを平文で取得するリスクを低減できます。
従来の VM やコンテナでは、ホスト側に強い権限を持つ者が実行中のデータを観測し得るという脅威が残ります。一方、CC ではハードウェアレベルの隔離とメモリ暗号化により、この脅威に対する防御を強化できます。
ただし、CC が強いのは「TEE の外側から覗かれる」脅威に対してであり、 適切なアプリケーション設計は変わらず重要です。この点については5章で詳しく説明します。
運用負荷を委託しつつ、処理中データの秘匿性を検証できる
ローカル LLM は、データを自社管理下に置ける有力な選択肢です。一方で、モデルや実行環境の運用、脆弱性対応、サーバー保全までを自社で担う必要があります。
適切に設計された CC 上の LLM サービスでは、こうした運用負荷を提供者に委託しながら、処理中データを提供者やクラウド管理者から秘匿し、その構成を Remote Attestation によって検証できます。重要なのは、CC を使うだけで自動的に安全になるわけではなく、ログ、外向き通信、学習・再利用経路、運用者アクセスを含めた設計とセットで成立する点です。
- 運用を提供者に任せられる:モデル更新・GPU 運用・スケーリング・脆弱性対応などを提供者に委託でき、自社の運用負担を軽減できます。
- 提供者・内部者リスクにも備えられる:ローカル運用でも、自社の特権管理者や侵害されたサーバーから処理中データが狙われるリスクは残ります。CC では、メモリ暗号化と隔離により、運用主体が自社か提供者かを問わず、TEE の外側から処理中データを読み取られるリスクを低減できます。
- 構成を検証できる:Remote Attestation により、「期待した TEE / CC GPU 上で、想定した構成が動いているか」を利用者側から確認できます。ただし、何を検証対象に含めるか、ログや通信をどう制御するかは、サービス側の設計に依存します。
4. 既存手段との比較
上記を踏まえて、SaaS 型 LLM・ローカル LLM・適切に設計された CC 上の LLM サービスを、企業が気になる観点で整理します。
観点 | SaaS 型 LLM | ローカル LLM | 適切に設計された CC 上の LLM サービス |
|---|---|---|---|
機密情報の扱い | 契約・設定・提供者の運用に依存 | 自社環境で統制しやすい | 提供者・クラウド管理者から処理中データを秘匿する設計が可能 |
運用・メンテナンス | 委託しやすい | 自社負担が大きい | 委託しやすい |
特権権限・基盤侵害時 | 提供者側の分離設計・インシデント対応に依存 | 平文メモリやログが攻撃対象になり得る | TEE 外からのメモリ読み取りを抑止しやすい。ただしアプリ経由の流出は別途対策が必要 |
安全性の確認 | 契約・規約・監査レポートに依存 | 自社の構成管理・監査に依存 | Remote Attestation により実行環境を技術的に検証可能 |
CC 上の LLM サービスの要点は、SaaS の運用の軽さと、ローカル LLM が持つデータ統制の考え方を組み合わせられる点です。さらに Remote Attestation によって、実行環境を利用者側から検証できる点が特徴です。ただし、この性質は CC を使えば自動的に得られるものではなく、ログ、通信、学習・再利用経路などの設計とセットで成立します。
では、安全性をどう設計で成立させるのか
CC は万能ではありません。ハードウェアによってメモリを暗号化し、Remote Attestation によって実行環境を検証できたとしても、それだけで LLM サービス全体の安全性が決まるわけではありません。
たとえば、TEE 上で動くライブラリに脆弱性があり、外部ストレージにプロンプトを送信するような処理が含まれていた場合、データがメモリ上で暗号化されていてもプロンプトは外部に流出し得ます。TEE は「外側から覗きにくい箱」を提供しますが、その箱の中で動くコードやライブラリの健全性は、別途設計・検証する必要があります。
特に LLM サービスでは、推論サーバーの責務を「推論と最低限の入出力処理」に絞り込むことが重要です。
推論だけに責務を絞る設計
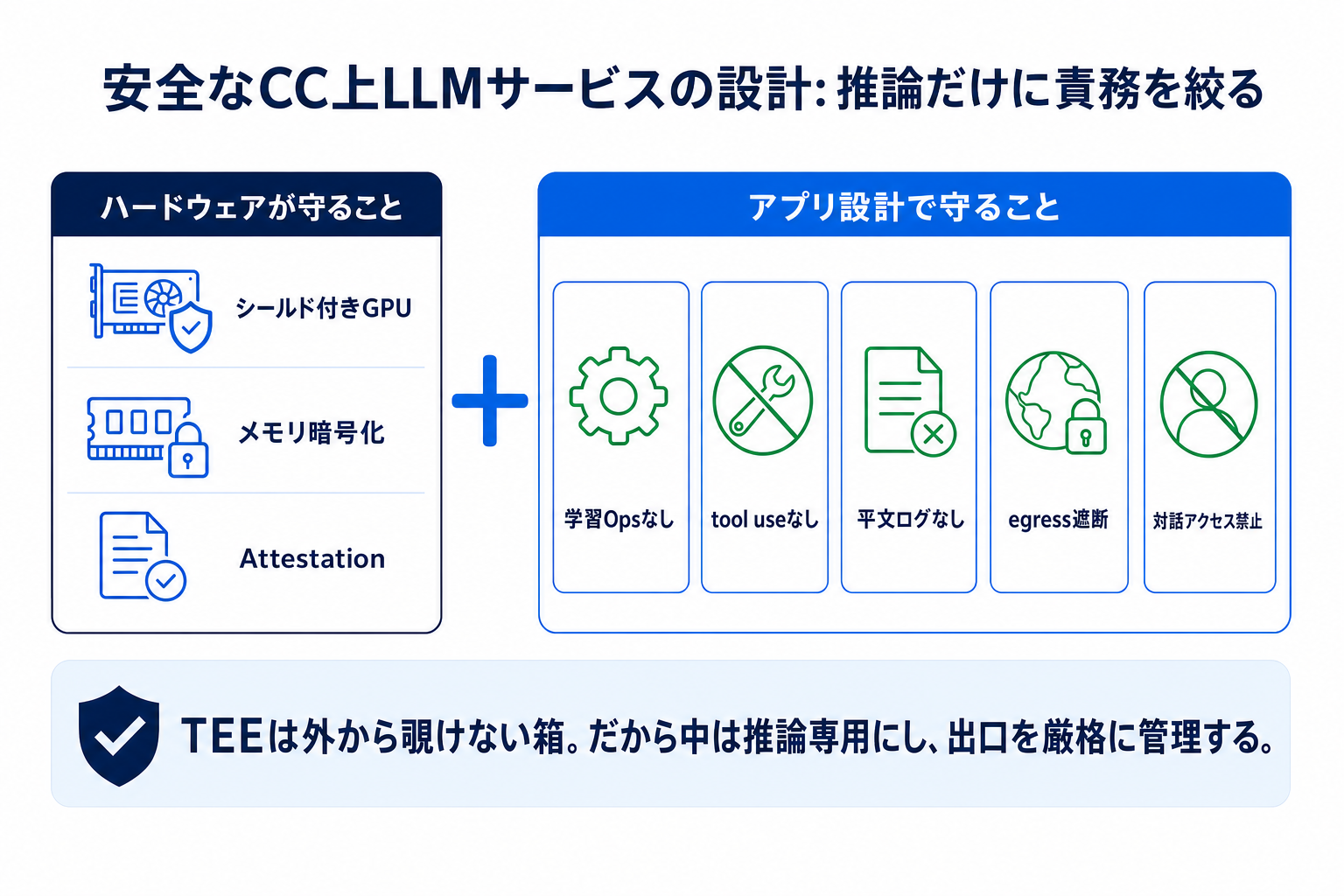
TEE という「外から覗けない箱」の中身を健全に保つため、責務を最小化します。大きく「データの再利用・副作用を断つ」観点と「データの滞留・流出経路を断つ」観点があります。
データの再利用・副作用を断つ
- 学習・再利用のための処理を組み込まない:受け取ったプロンプトや出力を、ファインチューニングやデータセット蓄積などに回す処理を推論サーバーに持たせません。具体的には、推論サーバーから学習用ストレージへ書き出す経路を設けず、入力は推論にのみ使い、処理後は破棄します。これにより、入力/出力が学習やデータセット蓄積に回らないことを、設計・コードレビュー・構成検証の観点から確認しやすくします。
- ツール呼び出し(tool use)を許可しない:外部 API 呼び出しやファイル操作などの副作用を持たせず、責務を「推論」だけに限定することで、攻撃面と情報の流出経路を最小化します。
データの滞留・流出経路を断つ
- ログ・テレメトリに平文を残さない:機密情報を含むプロンプトや出力をディスク・ログに書かず、処理後は不要になったデータをメモリ上に保持し続けないようにします。本稿で想定する構成でメモリを暗号化していても、平文ログに吐き出せば機密情報が流出する恐れがあります。
- 外向き通信(egress)を制御する:推論結果の返却など必要な通信を除き、TEE から任意の外部ネットワークへ出られないようにします。tool use 禁止の上位概念であり、仮に内部で情報を集められても、許可されていない外部送信先へ出られなければ、機密情報が流出するリスクを低減できます。
- 運用者に対話的アクセスを持たせない:SSH・シェル・デバッガなどで、提供者の運用担当者が TEE 内のプロセスに直接アクセスできる経路を設けないようにします。TEE の外側からの読み取りを防いでも、内部に入れる運用経路があると、処理中データを閲覧できる可能性が残るためです。
加えて、テレメトリの内容設計や、プロンプト/KVキャッシュの共有設計、といった部分も重要です。
6. Acompany の生成AI基盤
Acompany では、ここまで述べた「処理中データを秘匿する」「実行環境を検証する」「推論サーバーの責務を絞る」という考え方を取り入れた生成AI基盤を開発しています。
この基盤では、CC GPU 上で open-weight モデルを動かし、OpenAI API 互換のインターフェースで提供することで、既存アプリケーションから差し替えやすい形で秘匿性の高い推論を利用できるようにしています。
この生成AI基盤は、弊社の機密データや個人情報を守りながら使える生成AIチャットサービスの「Acompany セキュアチャット」や、機密ソースコードを守りながら AI コーディング支援を行う 「Acompany セキュアコード」 で活用されています。各サービスの詳細は公式ページをご覧ください。

まとめ
Acompany は「あらゆるデータとAI活用に、信頼を」をテーマに、秘密を守れるAIサービスを開発しています。
機密情報を守りながらAIを活用するイメージや、Acompany セキュアチャットの実際の操作画面・使い方は、Acompany公式YouTubeチャンネルでも紹介しています。ぜひあわせてご覧ください。
また、こうした「Confidential Computing × AI」の研究・開発に興味がある方へ。
Acompanyでは、一緒にプライバシーテックの領域で世界を目指してくれるメンバーを募集しています。少しでも興味を持っていただけた方は、ぜひカジュアル面談でお話ししましょう。
おすすめ記事一覧

.png)
外資IT大手の役員からなぜAcompanyへ?スタートアップで挑むAI時代の事業づくりとは【高橋亮祐×五十嵐修平】

IMAポリシーはどこまで信頼できるか
.png)
創業8年で実感した、人と文化と覚悟

JSAI2026スポンサー参加の裏側——Acompanyブースはこうしてできた

AWS Nitro Enclavesのセキュリティアーキテクチャ

差分プライバシーの20年とこれから——TPDPパネル討論を聴講して
.png)
後編:KV Cacheへの攻撃と防御 ── LLM推論インフラの安全を考える
.png)
前編:KV Cacheの仕組みと最適化手法 ── LLM推論を速くする技術を整理する

EUのデータ保護機関が注目する「Confidential Computing」とは?

「秘密計算の会社」だと思って入社したら、「Confidential AI の会社」になっていた。 — 入社1ヶ月、ITシステム部 / セキュリティの現場から
入力された情報は学習には使われませんが、念のため個人情報の入力はお控えください。